Introduction
Over the last few posts, I have been writing about how I implemented a “Similar Posts” component on my blog. In the first post, I presented an approach for recommending posts to users based on semantic similarity. In the second, most recent post, the concept was refined to include a filter to reduce the possibility of bad recommendations. In this third post, I will be looking at the feature from a developer perspective.
While working on the previous posts, I was using Astro’s dev mode quite a bit. With Astro, one can run the command npm run dev to host the site locally in dev mode. When edits are made to files, the build automatically refreshes. I noticed the time needed to refresh was much slower than before the embedding code was added. Upon closer inspection, I realized the creation of the embeddings was quite slow and would happen each time the site refreshed.
The Cost of Re-Embedding — and Why SQLite Wins
Each time Astro rebuilt the site, it was calling the OpenAI API to re-embed all the posts — even though the post content hadn’t changed. That’s both inefficient and costly. When an API call is made, the build is slowed down by network latency and computation times. With a cache, I can save the results of previous requests.
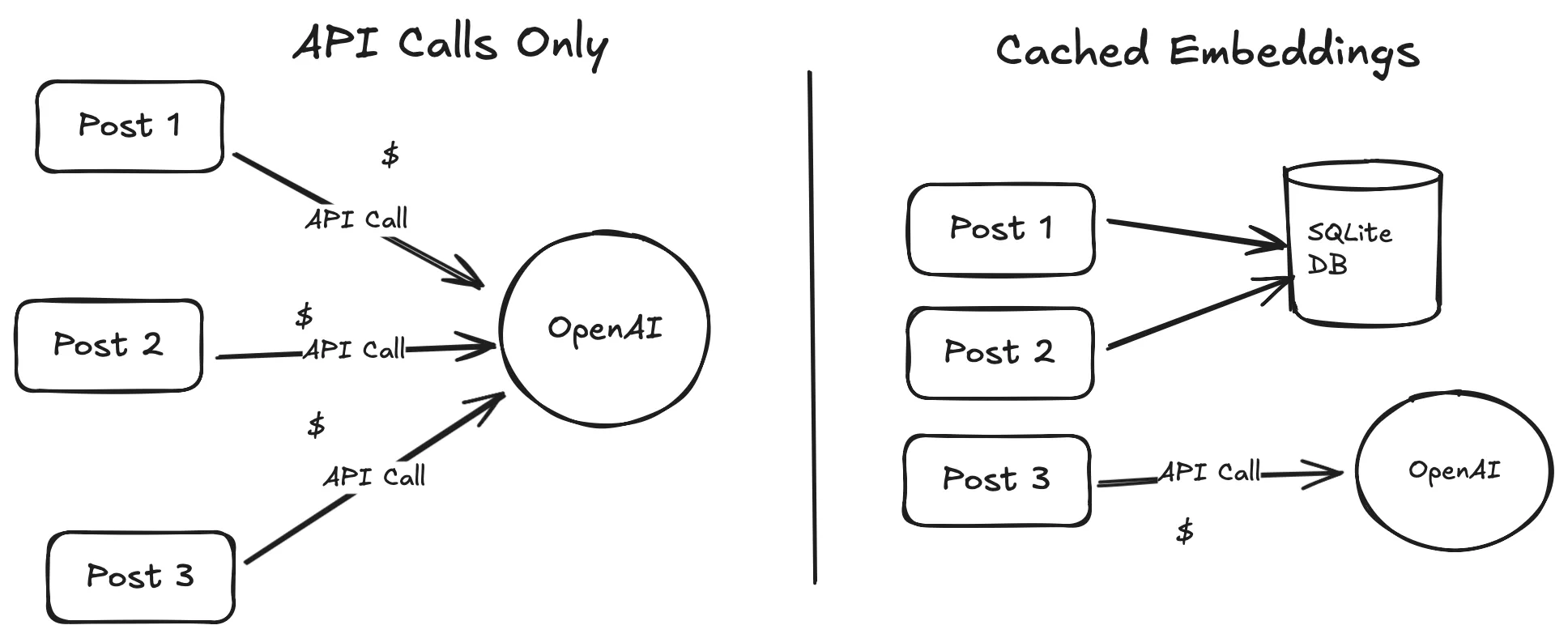
To avoid repeated calls and improve performance, I evaluated a few caching strategies. When compared to some of the other available options, SQLite presents itself as a very appealing solution. The options I looked at were as follows:
- A SQLite database.
- Cloudflare KV or D1.
- Astro DB.
- JSON file.
While my first instinct was to reach for just plain SQLite, I gave some thought towards Cloudflare services or the Astro DB service. Something which immediately ruled out the Cloudflare services was the fact my site is completely, statically generated. To use KV or D1, I would need to create and manage an API key.
With Astro DB, my thinking was that I am basically just using SQLite. Astro DB uses libSQL under the hood, and libSQL is a fork of SQLite. I found a Reddit thread about libSQL which made me think very carefully about using the service. One of the commenters mentioned the Redis debacle, and I realized for this project it would be better to stick to plain SQLite.
Lastly, the JSON idea came from OpenAI embeddings cookbook. The cookbook is written in Python and uses a pkl file for caching. An equivalent for my Astro project would be a JSON file. However, I still decided to go with the SQLite approach since it would be more scalable over time. For example, I could switch to a different programming language or move my database to the cloud via Astro DB or Turso.
Implementing the Cache in Your Astro Build
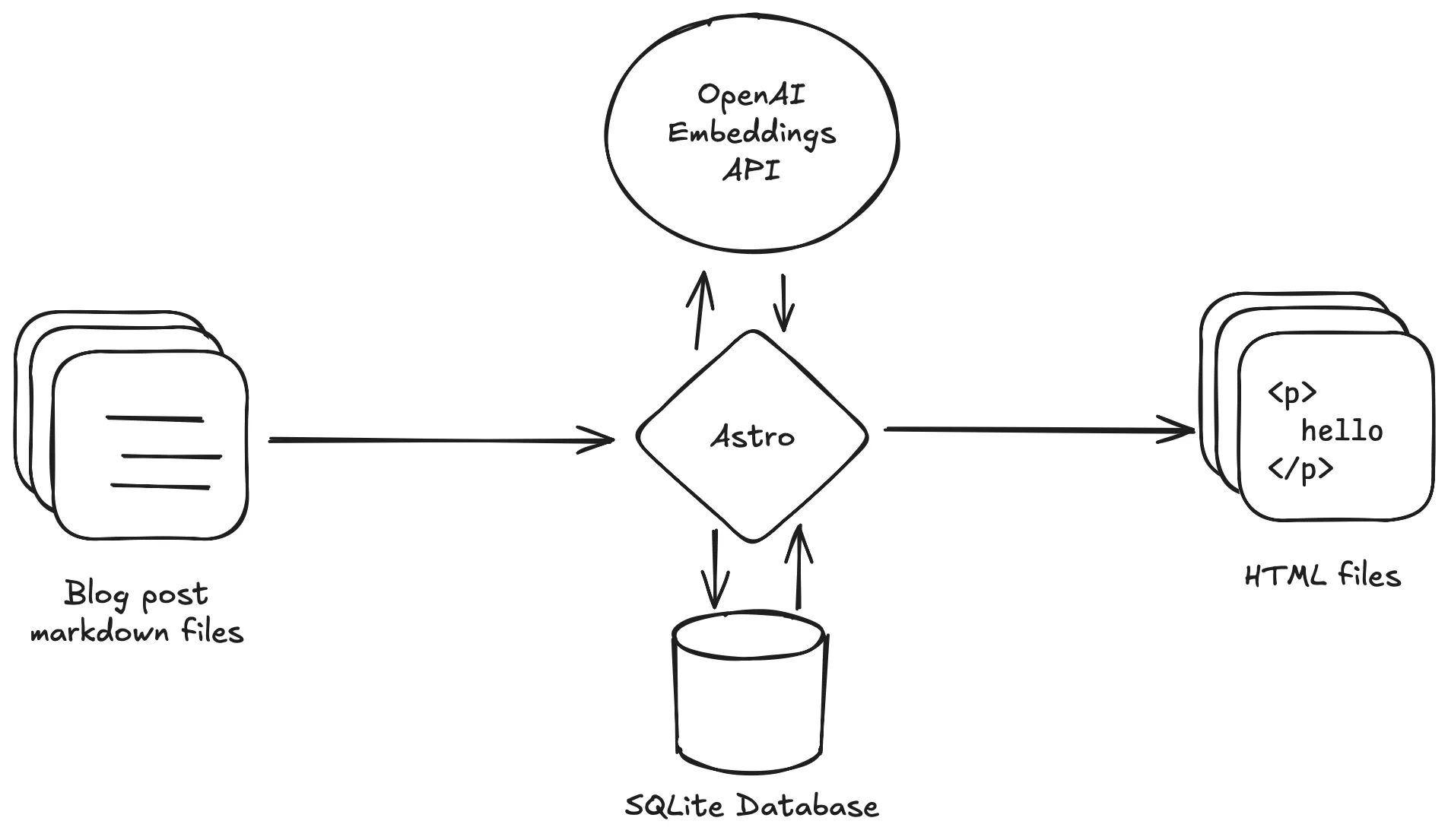
The caching mechanism will work as follows:
- Given a slug and body for a post, hash the post body. This ensures we can detect when post content has changed, even if the slug stays the same.
- Check if a record exists for the slug in the database.
- If a record does not exist, compute the embedding. Save the embedding and hash to the database. Return the embedding.
- If a record does exist and the hashes do not match, recompute the embedding. Save the new embedding and hash to the database. Return the embedding.
- If a record does exist and the hashes match, return the embedding from the database.
Implemented in code, this is what the embedding with caching function looks like:
// src/utils/openai.ts
const currentFilePath = fileURLToPath(import.meta.url);
const currentDir = dirname(currentFilePath);
const astroDir = resolve(currentDir, '../..', '.astro');
const dbPath = join(astroDir, 'embeddings.db');
if (!existsSync(astroDir)) {
mkdirSync(astroDir);
}
const db = new Database(dbPath);
db.exec(`
CREATE TABLE IF NOT EXISTS embeddings (
post_id TEXT PRIMARY KEY,
post_hash TEXT,
embedding TEXT
);
`); // Define the table for caching the embeddings.
type EmbeddingsRow = {
post_id: string;
post_hash: string;
embedding: string;
};
const getPostEmbedding = async (apiKey: string, post: PostContent): Promise<Embedding> => {
const {slug, content} = post;
const hash = createHash('sha256'); // Step 1
hash.update(content);
const hashedContent = hash.digest('hex');
const row = db.prepare('SELECT * FROM embeddings WHERE post_id = ?').get(slug) as EmbeddingsRow;
if (!row) { // Step 2/3. Embedding is not cached, so we generate one and save it.
const vector = await getEmbedding(apiKey, content);
const insert = db.prepare('INSERT INTO embeddings (post_id, post_hash, embedding) VALUES (?, ?, ?)');
insert.run(slug, hashedContent, JSON.stringify(vector));
return {
slug,
vector
};
} else if (row.post_hash !== hashedContent) { // Step 4. Post was updated, so we regenerate and save a new embedding.
const vector = await getEmbedding(apiKey, content);
const update = db.prepare('UPDATE embeddings SET post_hash = ?, embedding = ? WHERE post_id = ?');
update.run(hashedContent, JSON.stringify(vector), slug);
return {
slug,
vector
};
}
return {
slug,
vector: JSON.parse(row.embedding), // Step 5. Return the embedding from the cache.
};
};
// Helper method for common OpenAI requests.
const getEmbedding = async (apiKey: string, content: string): Promise<number[]> => {
const openai = getClient(apiKey);
const response = await openai.embeddings.create({
model: "text-embedding-3-small",
input: content
});
const vector = response.data[0].embedding;
return vector;
};Choosing the .astro Directory for the Cache
You might be wondering why the SQLite file is stored inside the .astro directory. This choice is intentional:
- Astro already uses this folder for build artifacts, so it’s not committed to version control.
- It’s automatically ignored in most setups (.gitignore, .prettierignore, etc.).
- Cloudflare Pages caches .astro/ between builds for up to seven days, which means the cache can persist across deploys without needing any additional configuration.
This setup keeps things tidy, avoids polluting the project root, and gives you build-time performance benefits for free if you’re deploying to Cloudflare. Caching could come in handy for situations where a lot of changes are being deployed within the seven day window.
Real-World Impact: Performance, Cost, and Stability
The best way to show how caching improves performance is with some data. To illustrate how caching helps, I ran three build scenarios for my Astro site:
- No caching.
- Caching enabled, but cache has not been created.
- Caching enabled, and cache exists.
For the first two scenarios, the commands were as follows:
rm -r .astro
time npm run buildFor the third scenario, I did not want to delete the .astro directory because that’s where the SQLite DB file lives. So for the third scenario, I just ran:
time npm run buildEach scenario was run five times. The total run time was saved for each run. I then computed the average of those times so that each scenario could be compared quantitatively. Here are the results:
| Scenario | Average Real Time (s) | Min (s) | Max (s) |
|---|---|---|---|
| Without caching | 16.9342 | 15.593 | 19.563 |
| With caching, no cache | 18.2872 | 16.403 | 21.159 |
| With caching, cache hit | 6.2574 | 6.011 | 6.575 |
As expected, the fastest build time is when the cache exists. A whole ten seconds is saved in comparison to the no-cache approach. Interestingly, the slowest time is when caching is enabled but no cache exists yet. This is probably because the inserts add a little extra time as compared to the no-caching approach.
Beyond just the numbers, this approach brought noticeable improvements in my development workflow:
- Speed: Local builds are significantly faster with cached embeddings. Once the cache is warm, I can refresh the site in under 7 seconds.
- Savings: Each API call to OpenAI costs time and money. By caching embeddings, I eliminate redundant requests and reduce usage-based costs over time.
- Stability: With everything stored locally, builds are more deterministic and can even run offline. That’s a big deal when working in CI environments or disconnected dev setups. Future improvements could even involve using local LLMs to further decouple from the web.
Caching doesn’t just improve numbers — it improves confidence in your toolchain.
Conclusion
Caching embeddings turned out to be one of those rare changes that improved everything at once — speed, cost, and reliability. By introducing a simple SQLite-based layer, I eliminated redundant API calls, dramatically reduced build times, and made local development feel snappy again.
It’s easy to reach for the cloud or a more complex tool, but sometimes the best solution is the simplest one. SQLite offered just the right balance of power and portability for my static Astro setup — and it’s flexible enough to evolve with the project.
If you’re building AI-powered features into your site, especially in a static or semi-static environment, don’t wait to add caching. You’ll save time, money, and frustration — and your build process will thank you.


