
Introduction
In a previous post, I described how I created a “Similar Posts” component for my blog. Originally, that was going to be a one-shot post. After deploying the new feature, I noticed that some of the recommended posts were irrelevant.
Why the Old Approach Fell Short
Shortly after publishing my last post, I was surfing the web and came across something I had not considered while implementing my “Similar Posts” feature. For example, when I was looking at my previous article AMD RX 6700 XT Overclocking: Unlocking Max Performance I noticed the following posts were displayed as similar:
While the first post seemed reasonable, I thought the other two seemed unrelated. This observation sent me on a search to determine if there was something I was missing. While asking ChatGPT, it suggested I should try to set a threshold score. However, ChatGPT’s suggestion did not include a way to calculate the score empirically. So I did some Google searches.
Unfortunately, most of the discussions on the first page of Google did not mention how to calculate a threshold. There was one GitHub repository which mentioned using K-means clustering, and there were some discussions on various forums like the OpenAI Developer Community. From reviewing these resources, I came to the conclusion there is no one-size-fits-all approach to determining a cutoff point.
Goals for the Similar Post Component
The component should do the following:
- Select only the most relevant posts to be displayed.
- Help users find content in a way which is not provided by other components on the page.
- Display nothing if no relevant posts can be found.
While I knocked around different ideas like calculating tag overlap or series alignment, the simplest approach seemed to be adding the cosine similarity threshold as a cutoff. To figure out what the threshold was, I needed to first gather some data and do some calculations.
Gathering the Data
To guide my decision-making, I created a new API endpoint to collect and analyze post similarity scores. An API endpoint would allow me to quickly display the results of important calculations like mean, median, and percentiles. The endpoint I created was src/pages/api/post-similarity.json.ts and it contains the following code:
// src/pages/api/post-similarity.json.ts
import { POST_EMBEDDINGS } from "@content/tags-and-posts";
import { getPairWiseSimilarityScores } from "@utils/related-posts";
export async function GET() {
const similarities = getPairWiseSimilarityScores(POST_EMBEDDINGS);
const sortedSimilarities = [...similarities].sort((a, b) => a - b);
// Do the math.
const min = Math.min(...similarities);
const max = Math.max(...similarities);
const mean = similarities.reduce((a, b) => a + b, 0) / similarities.length;
const half = Math.floor(similarities.length / 2);
const median = sortedSimilarities.length % 2
? sortedSimilarities[half]
: (sortedSimilarities[half - 1] + sortedSimilarities[half]) / 2
const p90 = sortedSimilarities[Math.floor(similarities.length * 0.9)];
const p75 = sortedSimilarities[Math.floor(similarities.length * 0.75)];
// Return the results as JSON.
return new Response(
JSON.stringify({
min,
max,
mean,
median,
p75, // 75th percentile
p90, // 90th percentile
numberOfScores: similarities.length, // For sanity check.
similarities
})
);
}For clarification, the method getPairWiseSimilarityScores is new and was added to the src/utils/related-posts.ts file. The function computes cosine similarity for all pairs of posts on the site. The function does not compare posts to themselves. Here’s the code for the function:
// src/utils/related-posts.ts
const getPairWiseSimilarityScores = (embeddings: Embedding[]) => {
const pairs: number[] = [];
for (let i = 0; i < embeddings.length; i++) {
// Start inner loop at i + 1 to not compute similarity between a post and itself.
for (let j = i + 1; j < embeddings.length; j++) {
const sim = getCosineSimilarity(embeddings[i].vector, embeddings[j].vector);
pairs.push(sim);
}
}
return pairs;
};With the array of scores, I was able to see a clear picture of the kinds of posts I have been writing. Here’s what I saw in the JSON returned from the endpoint:
| Calculation Type | Result |
|---|---|
| Min | 0.08 |
| Max | 1 |
| Mean | 0.49 |
| Median | 0.58 |
| p75 | 0.66 |
| p90 | 0.72 |
| Number of Scores | 496 |
For the sanity check “Number of Scores”, this was just to confirm I calculated the correct number of pair-wise cosine similarity scores. The expected value was (n x (n - 1)) / 2 where n is the number of posts. With 32 posts, we have (32 x 31) / 2 which is 496.
Upon initial review of these results, I first tried to set the threshold at 0.72 so only the most relevant posts would be displayed. However, when I went through all the articles I noticed a lot only had one or two posts showing up as similar. This didn’t seem quite right to me. Knowing that there was a wide dispersal of scores from 0.08 to 1, I decided to try and visualize the data.
To better understand the spread of scores, I exported the similarities array from the API’s JSON response into Google Sheets and created a histogram:
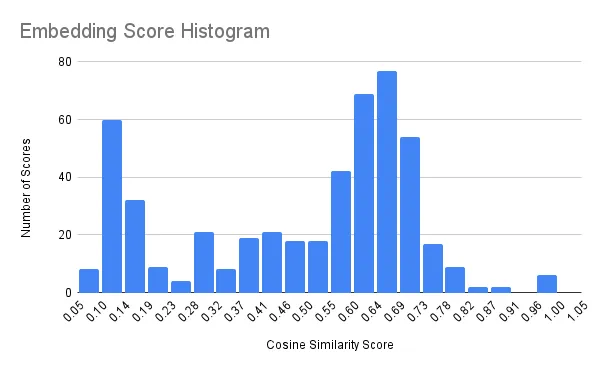
To me, it looks like a bimodal distribution. Usually, when a bimodal distribution is observed it indicates there are two populations being measured. From this, we can ascertain the data has a dense cluster of topic similarity around 0.65, since that is the value in the middle of the upper mode. Interestingly, this is pretty close to the 75th percentile. The lower mode maybe indicates a cluster of loosely related topics. We can also see the 90th percentile value of 0.72 only allows a very small number of posts to pass the cutoff.
How the Component Works Now
Selecting only posts with a cosine similarity at or above 0.65 should allow for the most number of posts with a high level of semantic similarity to be displayed. With that in mind, I had to modify the code used for gathering related posts.
The main change is now the “Similar Components” section could have less than three articles listed, or not appear at all, because of the threshold filtering. Previously, all posts had more than three similar articles. With this new approach, articles may not have any other post pass the threshold.
With the threshold hard-coded into the file containing the post collecting function, this is what src/utils/related-posts.ts was updated to:
// src/utils/related-posts.ts
const COSINE_THRESHOLD = 0.65; // The hard-coded threshold cosine similarity score.
const getSlugToMostRelatedPostsMap = (embeddings: Embedding[]) => {
const slugToMostRelatedPosts: Map<string, ScoredPost[]> = new Map();
for (const a of embeddings) {
const sims: ScoredPost[] = embeddings
.filter(b => b.slug !== a.slug)
.map(b => ({
slug: b.slug,
score: getCosineSimilarity(a.vector, b.vector),
}))
.filter((c) => COSINE_THRESHOLD <= c.score) // New step to only allow posts at or over the threshold.
.sort((a, b) => b.score - a.score)
.slice(0, 3);
slugToMostRelatedPosts.set(a.slug, sims);
}
return slugToMostRelatedPosts;
};Conveniently, the way I developed my “Similar Posts” component prevents it from being displayed when no similar posts are found. See my last article for the full code, but pay attention to this part:
---
// src/components/blog/SimilarPosts.astro
// ...
---
{
posts.length > 0 && (
<!-- HTML for the component here -->
)
}The posts.length > 0 is a logical gate to prevent the component from appearing. With an empty list, no HTML is rendered.
Future Considerations
The data provided by the embeddings opens up interesting avenues of exploration. For example, it could be paired with search performance data from Google Search Console to help me determine which posts can be archived. A post without any search clicks or embedding connections could be a target for archiving. On the flip side, a post with lots of embedding connections and good search results might indicate an opportunity for content growth.
This makes me want to prioritize two things from a site owner perspective:
- Replace image slugs with full image URLs in markdown before cross-posting.
- Automatically update posts on other platforms.
If I want to auto update posts on DEV and Hashnode, I need to first solve the image URL problem for the markdown bodies.
Conclusion
Refining this feature reminded me that building with AI isn’t just about plugging in smart tools—it’s about constantly validating whether the results actually make sense. What looks good on paper (or in code) doesn’t always translate to a meaningful experience for readers. By stepping back, analyzing the data, and adjusting a single threshold, I was able to make my “Similar Posts” component both smarter and simpler.
As with any machine learning-driven feature, relevance isn’t automatic—it’s earned through iteration.


