Note (April 9, 2026): I’ve disconnected from Hashnode and removed the live integration code from this site. This post is preserved as a record of how that integration worked.
Introduction
Cross-posting blog content across multiple platforms can be a powerful way to expand your reach and engage with different audiences. However, manually syncing posts to each platform can be time-consuming and prone to inconsistencies. To solve this, I created a custom integration for Astro—a modern static site generator—to automatically sync my blog posts to Hashnode via its GraphQL API.
This integration allows me to maintain full control over formatting, save valuable time, and seamlessly extend the visibility of my content. In this post, I’ll share the challenges I encountered, the solutions I implemented, and the step-by-step process of creating this integration. Whether you’re looking to automate your own cross-posting workflow or curious about building custom Astro integrations, this guide has something for you.
Why I Created This Integration
Logarithmic Spirals embodies recursive spirals. From its inception, I have developed it under the meta concept of building a blog about building a blog. As I add features, I create content. As I create content, I create features. However, at a certain point the concept needs to spiral outward beyond the confines of the Logarithmic Spirals domain. DEV has provided a good starting point for this, but I’ve been wanting to expand beyond it for some time.
Hashnode was my next goal, but I was stymied by difficulties in getting my existing content to automatically sync with it. My first attempt was with RSS since that’s what I use for DEV. However, Hashnode and DEV proved to be too different in their support of RSS imports. Subsequently, I put Hashnode to the side.
Reasons for me wanting to explore an integration:
- Future potential to post to other platforms.
- Tighter control over formatting and presentation on other platforms.
- Potential to use the DEV API.
What kicked off another look into this for me was my previous work on figuring out how to sync DEV posts with my Astro site. Once I realized I could pull in posts from external sources, the path forward on posting to other platforms became clearer. This set the stage for developing an efficient, automated way to cross-post to Hashnode while keeping my workflow lean and cost-effective.
Finding the Right Solution
One big issue I found right off the bat with integrations is integrations don’t have access to import.meta.env
variables. My first attempt at writing a Hashnode script relied on other, existing scripts which in turn relied
on environment variables being available from the Astro runtime. If I were to continue down that path, I would’ve
needed to rewrite multiple files to support execution from outside the Astro runtime.
After assessing the problem, I came up with the following solutions:
- Have a static endpoint which produces JSON for all the posts. Create an integration which runs on build completion. Read the JSON from the endpoint and then post to the necessary location. Delete the JSON file when finished.
- Create a component which only runs once per build and only runs during production builds.
- Modify the content collection script to post the drafts to Hashnode when running in production.
- Write some kind of app (like a cronjob) which could poll an endpoint on the site for new content.
Right off the bat, I want to avoid writing any additional code which runs outside of the static site generation flow. I have been committed to keeping this site’s costs at, or extremely close to, zero. Running additional apps or serverless functions would prevent me from achieving this goal.
Of these options, choice one seemed the best because the drafts would only be created when the build is successful. I didn’t want to be creating drafts during unsuccessful builds or during local development because that would make maintenance of the drafts on Hashnode more difficult. Additionally, a better solution to start with would make it easier to skip the draft step in the future.
Cross-Post Algorithm
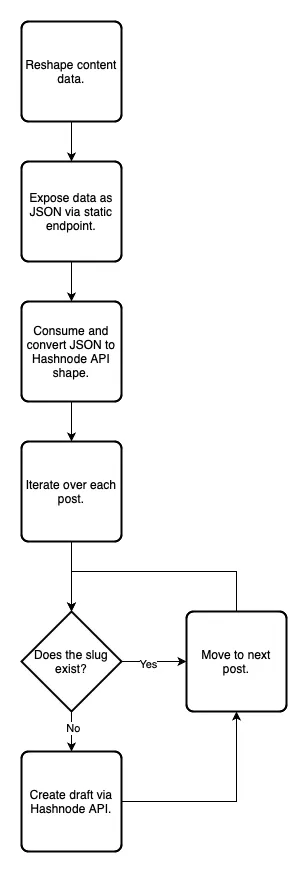
Outline
- Restructure content data to the shape needed by the integration.
- Expose the data as JSON via a static endpoint
src/pages/api/posts-for-hashnode.json.ts. - Consume the JSON via integration API in the
astro:build:donestep. - Convert the JSON to the shape recognized by the integration.
- Iterate over each post and check if a slug already exists for a draft or post on the target Hashnode publication.
- If the slug does not exist, create a new draft via Hashnode’s API. Otherwise, move to the next post.
Here’s a visualization of this algorithm as a flow chart:
The Code
First, I have the code for the static endpoint. Here’s how I pass the content data to the integration::
// src/pages/api/posts-for-hashnode.json.ts
import { POSTS } from "@content/tags-and-posts"; // This is an array of post data.
import type { HashnodePost } from "@utils/hashnode";
export async function GET() {
const postData: HashnodePost[] = POSTS
.filter(post => post.collection !== 'dev-to') // Going to work on DEV posts in the future.
.map(post => {
return {
title: post.data.title,
subtitle: post.data.description,
contentMarkdown: post.body,
publishedAt: post.data.pubDate.toISOString(),
slug: post.slug,
tags: post.data.tags.map(tag => {
return {
name: tag,
slug: tag
};
}),
coverImageUrl: post.data.heroImage.src
};
});
return new Response(
JSON.stringify(postData)
);
}
The API code is relatively simple. I just take the existing post data saved in the POSTS variable, filter out any
DEV posts, and then reshape the data to fit the HashnodePost shape. The data is then converted to a JSON string for
later consumption by the integration.
The integration code is in a file called src/integrations/cross-post.ts and looks like this:
import { createHashnodeDrafts, type HashnodePost } from "../utils/hashnode";
import type { AstroIntegration, RouteData } from "astro";
import fs from 'fs';
import 'dotenv/config';
const hashnodePublicationHost = "logarithmicspirals.hashnode.dev";
const crossPost: AstroIntegration = {
name: 'cross-post',
hooks: {
'astro:build:done': async ({ routes, logger }) => {
let postJsonRoute: RouteData | undefined = undefined;
for (const route of routes) {
if (route.pathname === '/api/posts-for-hashnode.json') {
postJsonRoute = route;
break;
}
}
if (postJsonRoute && postJsonRoute.distURL) {
const filePath = postJsonRoute.distURL.pathname;
const fileContent = fs.readFileSync(filePath, 'utf8');
const data: HashnodePost[] = JSON.parse(fileContent);
const token = process.env.HASHNODE_TOKEN;
if (token) {
await createHashnodeDrafts({
hashNodeToken: token,
publicationHost: hashnodePublicationHost,
posts: data
}, logger);
} else {
logger.error('No hashnode token configured');
}
fs.rmSync(filePath.replace('/posts-for-hashnode.json', ''), { recursive: true });
}
}
}
};
export default crossPost;
The integration runs when the build completes. I loop over the routes and look for the built version of the API endpoint. Once I find it, I read the generated JSON. After checking for the existence of the Hashnode access token, I proceed to create the drafts. Lastly, I remove the JSON file from the build output.
Finally, I have the code which creates the drafts through the Hashnode API (note I’ve commented out some things which I will fill in later):
import { gql, GraphQLClient } from "graphql-request"
import { SITE } from "../consts";
import type { AstroIntegrationLogger } from "astro";
const HASHNODE_URL = 'https://gql.hashnode.com';
// GraphQL queries/mutations here.
// Type definitions here.
const createHashnodeDrafts = async (args: DraftCreationArguments, logger: AstroIntegrationLogger) => {
const grapQLClient = new GraphQLClient(HASHNODE_URL, {
headers: {
authorization: args.hashNodeToken
}
});
let draftsCreated = 0;
for (let i = 0; i < args.posts.length; i++) {
const post = args.posts[i];
const slug = post.slug;
const postWithSlug: ExistingPostResult = await grapQLClient.request(getPostBySlug,
{ publicationHost: args.publicationHost, slug });
const draftSlugs = postWithSlug.publication.drafts.edges.map(edge => edge.node.slug);
if (!(postWithSlug.publication.post || draftSlugs.includes(slug))) {
logger.info(`No post exists on Hashnode with slug ${slug}`);
const created = await createDraft(grapQLClient, postWithSlug.publication.id, post, logger);
if (created) {
draftsCreated += 1;
}
} else {
logger.info(`Post or draft exists on Hashnode with slug ${slug}`);
}
}
logger.info(`Hashnode drafts created = ${draftsCreated}`);
};
const createDraft = async (
grapQLClient: GraphQLClient, publicationId: string, post: HashnodePost, logger: AstroIntegrationLogger
) => {
const draftVariables = {
input: {
title: post.title,
subtitle: post.subtitle,
contentMarkdown: post.contentMarkdown,
publishedAt: post.publishedAt,
slug: post.slug,
tags: post.tags,
settings: {
enableTableOfContent: true,
activateNewsletter: true
},
originalArticleURL: SITE + '/blog/' + post.slug + '/',
publicationId: publicationId,
disableComments: false,
coverImageOptions: {
coverImageURL: SITE + post.coverImageUrl
}
}
};
try {
await grapQLClient.request(createDraftMutation, draftVariables);
return true;
} catch (err) {
logger.error(JSON.stringify(err.response.errors));
}
return false;
};
export {
createHashnodeDrafts
}
In broad strokes, the createHashnodeDrafts function:
- Creates a GraphQL client.
- Loops over the posts and checks if a Hashnode post or draft already exists with the post’s slug.
- If a no such slug is taken, the post is reshaped and used to create the final draft slug.
Here’s what the removed query, mutation, and types look like:
const getPostBySlug = gql`
query GetPostBySlug($publicationHost: String!, $slug: String!) {
publication(host: $publicationHost) {
id
post(slug: $slug) {
id
}
drafts (first: 50) {
edges {
node {
slug
}
}
}
}
}
`;
const createDraftMutation = gql`
mutation CreateDraft($input: CreateDraftInput!) {
createDraft(input: $input) {
draft {
id
canonicalUrl
}
}
}
`;
type ExistingPostResult = {
publication: {
id: string;
post: {
id: string;
};
drafts: {
edges: Array<{
node: {
slug: string;
};
}>;
};
}
}
export type HashnodeTag = {
name: string;
slug: string;
};
export type HashnodePost = {
title: string;
subtitle: string;
contentMarkdown: string;
publishedAt: string;
slug: string;
tags: HashnodeTag[];
coverImageUrl: string;
};
type DraftCreationArguments = {
hashNodeToken: string;
publicationHost: string;
posts: HashnodePost[];
}
A keen observer will note there’s a drawback to the getPostBySlug query. There’s a max limit of 50 slugs which
can be returned. From my research, it seems like there isn’t a way to look up a draft by slug via the GraphQL API. This
is unfortunate, and makes things a little trickier. While this isn’t an issue for me now, it could be if I ever end up
with more than 50 drafts.
Drawbacks to the Solution
As previously mentioned, one drawback of this approach is in how Hashnode’s API is designed. If I wanted to scale this up in the future, I would have to figure out a way to quickly check if a slug is already taken. My intuition tells me a database might be needed for that. Some other drawbacks are:
- There’s no way to look up drafts by slug on Hashnode. Need to be mindful not to make too many or I might end up with duplicate drafts.
- JSON from the endpoint has to match the shape understood by the integration. This is a tight coupling.
- Creating an endpoint just to later delete it feels hacky.
Benefits of the Solution
On the other hand, there are significant benefits to this custom integration:
- Streamlines cross-posting to Hashnode, eliminating manual uploads.
- Keeps hosting and operations costs at zero.
- Built with future integrations and enhancements in mind.
The biggest benefit is that I can push the original markdown to Hashnode. In the past, the RSS imports would always have weird formatting issues and would require a lot of manual editing. The only manual editing I have to do now is adjust the image links because of how I store image files relative to the markdown. Furthermore, these benefits better position me for some future updates.
Follow-up Enhancements
Building off of this new feature, I want to make the following enhancements to my site:
- Move DEV cross-posting away from RSS.
- Create an integration for automatic BlueSky posts.
- Research cross-posting on daily.dev and Hackernoon.
- Dial in the cross-post algorithm to allow direct publishing without initial draft creation.
Generally speaking, these enhancements will help me continue to expand the reach of Logarithmic Spirals.
Conclusion
Building a custom Astro integration to cross-post blog content to Hashnode has been a rewarding project. It not only simplifies my workflow but also ensures my content reaches a wider audience with minimal manual effort. By leveraging Astro’s build hooks and Hashnode’s GraphQL API, I’ve created a solution that’s efficient, scalable, and tailored to my needs.
While there are still areas for improvement—such as refining the draft handling process and exploring direct publishing options—this integration is a strong foundation for future enhancements. As I continue to expand its capabilities, I plan to explore integrations with other platforms like BlueSky, Hackernoon, and daily.dev.
If you’ve been looking for ways to automate your content distribution or are interested in creating your own Astro integrations, I hope this post has provided some valuable insights. I’d love to hear your thoughts—what challenges have you faced in automating your workflow, and what platforms would you like to see integrated next? Let’s keep the conversation going!